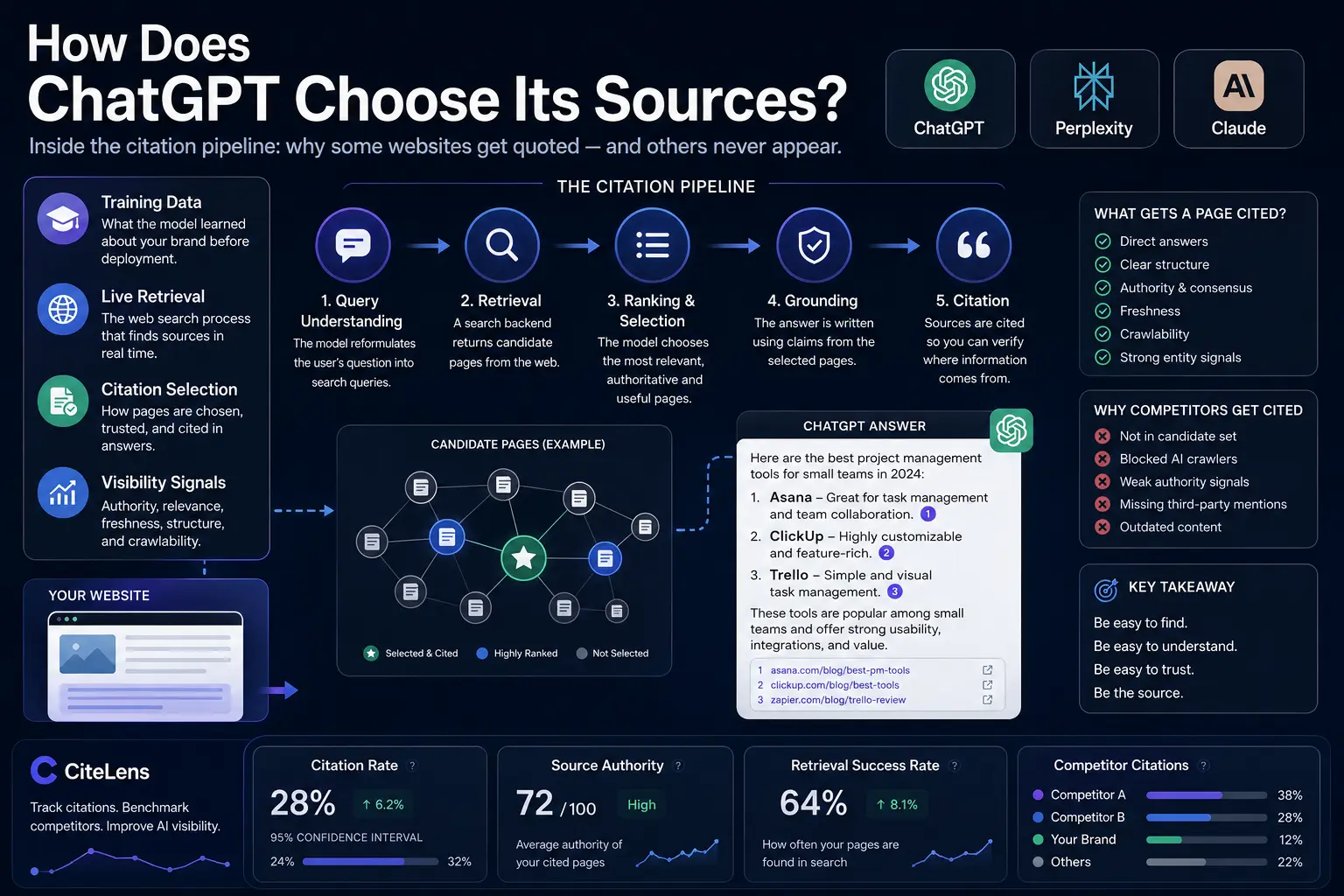
How does ChatGPT choose its sources?
When ChatGPT cites a page, it isn't random. Here's the pipeline behind a cited answer — and the concrete signals that decide whether your domain is the one it quotes.
Two different mechanisms: training and retrieval
Before you can influence what ChatGPT cites, you have to understand that it pulls knowledge from two very different places. The first is its training data: everything the model absorbed about your brand and your category during pre-training, frozen at a cutoff date. The second is live retrieval: when the model runs a web search mid-answer, fetches a handful of pages, and grounds its response in them — adding the little citation markers you see at the end of sentences.
These two mechanisms reward completely different things. Training-time presence is about your long-term footprint across the web — how consistently your brand is described, in which contexts, and on which sources the model considers authoritative. Retrieval-time presence is about right now: can the search layer find a relevant page on your domain, is it reachable to the crawler, and is it quotable enough to ground a sentence? When ChatGPT shows numbered citations, you're almost always looking at the retrieval mechanism, and that's the one you can move fastest.
What actually happens inside a cited answer
A grounded ChatGPT answer goes through a rough pipeline, and each stage is a place where you can win or lose visibility:
- Query understanding — the model reformulates the user's question into one or more search queries. If your content is written around the phrasing real users type, you're already aligned with this step.
- Retrieval — a search backend returns candidate pages. If your page never enters this candidate set, nothing else matters; you've lost before ranking even begins.
- Selection and ranking — the model picks which of those candidates to actually read and trust, weighing relevance, authority and how directly each page answers the query.
- Grounding and citation — the model writes the answer using quotable claims from the selected pages and attaches a citation to the source it leaned on.
The signals that get a page cited
Across these stages, a consistent set of properties separates pages that get cited from pages that don't. None of them are secret — they're the same fundamentals that made content trustworthy in the SEO era, sharpened for a machine that quotes rather than ranks.
- Direct answers — pages that state the answer plainly, near the top, in a sentence a model can lift, beat pages that bury it under preamble.
- Structure — clear headings, short factual paragraphs, lists and tables make content easy to parse and easy to quote.
- Authority and consensus — when multiple sources the model already trusts say the same thing about you, you become the safe, citeable consensus.
- Freshness — for anything time-sensitive, recently updated pages are preferred; stale content is quietly skipped.
- Crawlability — if AI crawlers like GPTBot can't fetch your page, you are invisible to retrieval no matter how good the content is.
Why your competitors get cited and you don't
When a brand isn't cited, the cause is rarely that the content is worse. More often it's one of a few structural problems: the page never made it into the retrieval candidate set for the queries that matter; the domain blocks or stalls AI crawlers; or the third-party sources the model trusts — directories, review sites, editorial roundups — name competitors and never mention you. In that last case, the fix isn't on your own site at all. It's earning mentions on the pages the model already reads.
This is the uncomfortable truth of generative visibility: you can have excellent content and still be absent from the answer, simply because the engine never reached your page or never had a reason to trust it over an established competitor.
How to become a source ChatGPT reaches for
The practical playbook is straightforward. Publish citeable, factual content that answers real questions in the first paragraph. Keep your site fully crawlable to AI bots. Earn mentions and links on the third-party sources that already get quoted in your category. Use clear entity signals — consistent naming, structured data, an unambiguous description of what you do — so the model can connect your brand to its category with confidence. Do this consistently and you stop chasing the answer; you become part of it.
But none of this is measurable by eye. To know whether any of it is working, you have to track which domains get cited for your prompts, across engines, over time — which is exactly what the next step is about.