How to track your AI visibility across ChatGPT, Perplexity and Claude
Spot-checking AI answers by hand tells you almost nothing. Here's how to track your AI visibility properly — as a metric you can trust and trend over time.
Why manual spot-checks fail
The instinct is to open ChatGPT, ask your key question, and see if you show up. The problem is that generative answers are non-deterministic. Ask the same prompt twice and you can get two different lists of brands. Switch from ChatGPT to Perplexity and the cited sources change completely. Ask from another country, or a week later, and the picture shifts again.
So a single manual check is one sample from a noisy distribution. It can flatter you with a mention you'd rarely get, or hide you on the one run you happened to try. Building decisions on it is like judging your search rankings by refreshing the page once.
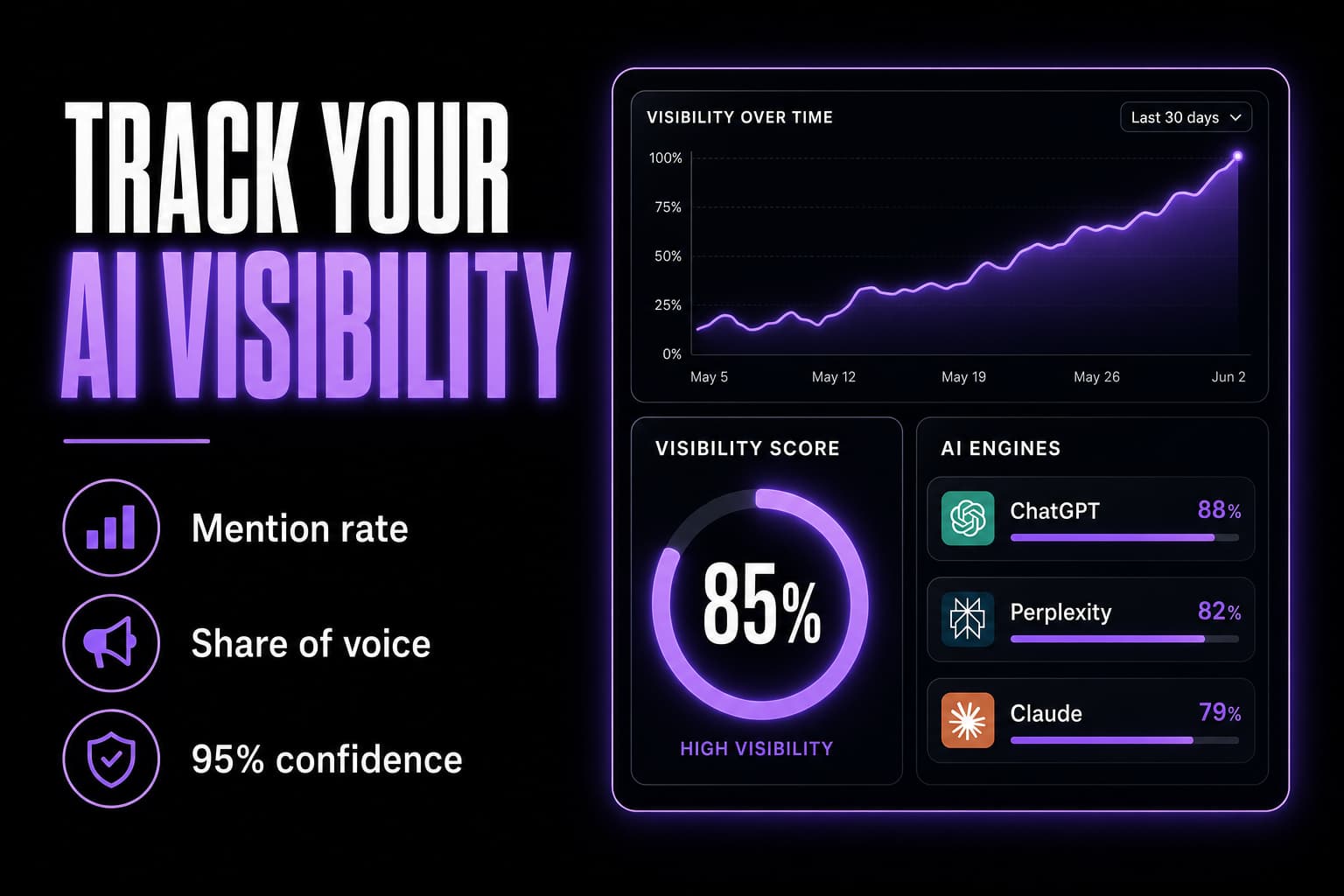
What you actually need to measure
Proper AI-visibility tracking turns those noisy answers into stable metrics. The ones that matter:
- Mention rate — out of many runs of a prompt, how often the engine names your brand.
- Citation rate — how often it cites your domain as a source. These are different signals; you can be named without being cited, and vice versa.
- Share of voice — your visibility relative to the competitors that appear alongside you on the same prompts.
- Per-engine breakdown — your numbers on ChatGPT vs Perplexity vs Claude, since they retrieve and reason differently.
- Trend over time — whether your visibility is rising or eroding as you do GEO work and as the models change.
How to track it rigorously
The method mirrors good measurement anywhere: run each prompt many times, across the engines that matter, and aggregate. Because each run is a yes/no on 'were you mentioned', you can compute a rate with a confidence interval — a 95% CI tells you whether a 40% mention rate is real signal or could just be noise from a small sample. Track the same prompts on a schedule so you're comparing like with like over time, and always capture who else appeared, so a drop in your share of voice points you straight at the competitor that's winning.
Doing this by hand across dozens of prompts, three engines and repeated runs isn't realistic — the combinatorics alone make it a full-time job, and you'd still lack the statistics to trust the result.
Tracking it with CiteLens
This is exactly what CiteLens automates. You define your prompts once; it runs them repeatedly across ChatGPT, Perplexity and Claude, computes your mention and citation rates with a 95% confidence interval, benchmarks your share of voice against the competitors stealing your answers, and tracks all of it over time. Instead of guessing from a manual spot-check, you get an AI-visibility metric you can actually manage — with a clear action list for raising it.